Solvers (求解器)#
指南 conda install 没有深入探讨求解器这个黑盒子的细节。它确实提到了高层级的 Solver API 以及 conda 如何期望从中得到一个事务 (transaction),但我们从未了解求解器内部发生了什么。我们只涵盖了以下三个步骤
细节很复杂,但本质上,求解器将:
将请求的软件包、命令行选项和前缀状态表示为
MatchSpec对象查询索引 (index),以找到满足这些约束的最佳匹配
返回
PackageRecord对象列表。
我们如何将前缀状态和配置转换为 MatchSpec 对象列表?这些对象如何转化为 PackageRecord 对象列表?这些 PackageRecord 对象从哪里来?我们将在本文中详细介绍这些方面。
MatchSpec vs PackageRecord#
首先,让我们定义每个对象的作用
PackageRecord对象表示一个具体的软件包 tarball 及其内容。它们遵循 特定的命名约定 并公开几个字段。在 类代码 中直接检查它们。MatchSpec对象本质上是一种查询语言,用于查找PackageRecord对象。在内部,conda会将您的命令行请求 (例如numpy>=1.19,python=3.*或pytorch=1.8.*=*cuda*) 转换为此类的实例。这种查询语言有其自己的语法和规则,详细信息请参见 此处。MatchSpec对象最重要的字段是:name: 软件包的名称 (例如pytorch);总是需要的。version: 版本约束 (例如1.8.*);可以为空,但如果设置了build,则将其设置为*,以避免.conda_build_form()方法出现问题。build: 构建字符串约束 (例如*cuda*);可以为空。
从 PackageRecord 实例创建 MatchSpec 对象
您可以使用 .to_match_spec() 方法从 PackageRecord 实例创建一个 MatchSpec 对象。这将创建一个 MatchSpec 对象,其字段设置为完全匹配原始 PackageRecord。
请注意,有两个 PackageRecord 子类具有额外的字段,因此我们需要区分三种类型,它们都很有用:
PackageRecord: 索引 (频道) 中存在的记录。PackageCacheRecord: 缓存中已提取的记录。包含磁盘 tarball 路径及其提取目录的额外字段。PrefixRecord: 前缀中安装的记录。与上述相同,外加构成软件包的文件以及它们在前缀中链接方式的字段。它还可以包含有关哪个MatchSpec字符串导致安装此记录的信息。
远程状态:索引#
因此,求解器接受 MatchSpec 对象,查询索引以获得最佳匹配,并返回 PackageRecord 对象。完美。什么是索引?它是聚合请求的 conda 频道到一个单一实体的结果。有关更多信息,请查看 获取索引。
本地状态:前缀和上下文#
当您执行 conda install numpy 时,您是否认为求解器只会看到类似 specs=[MatchSpec("numpy")] 的内容?嗯,没那么快。用户给出的显式指令只是我们将发送给求解器请求的一部分。其他隐式状态也会被考虑在内,以构建最终请求。即,您的前缀的状态。总的来说,这些是求解器请求的要素:
环境中已存在的软件包,如果您不是创建新环境。这通过
conda.core.prefix_data.PrefixData类公开,该类通过.iter_records()提供迭代器方法。正如我们之前看到的,这将产生conda.models.records.PrefixRecord对象,这是已安装记录的PackageRecord子类。您在该环境中执行的过去操作;历史记录。这是您过去运行的所有
conda install|update|remove命令的日志。换句话说,先前操作匹配的 specs 将在求解器中获得额外的保护。包含在激进更新列表中的软件包。这些软件包始终包含在任何请求中,以确保它们在任何情况下都保持最新。
通过
.condarc中的pinned_packages或在$PREFIX/conda-meta/pinned文件中定义的固定到特定版本的软件包。在新环境中,包含在
create_default_packages列表中的软件包。这些规范被注入到每个conda create命令中,因此求解器会将它们视为用户显式请求的。最后,用户正在请求的规范。有时这是显式的 (例如
conda install numpy),有时则有点隐式 (例如conda update --all告诉求解器将所有已安装的软件包添加到更新列表)。
所有这些信息来源都会产生许多 MatchSpec 对象,然后以非常特定的方式组合和修改这些对象,具体取决于命令行标志及其来源 (例如,来自固定软件包的规范不会被修改,除非用户明确要求)。这种逻辑很复杂,将在接下来的章节中介绍。更技术性的描述也可在 技术规范:求解器状态 中找到。
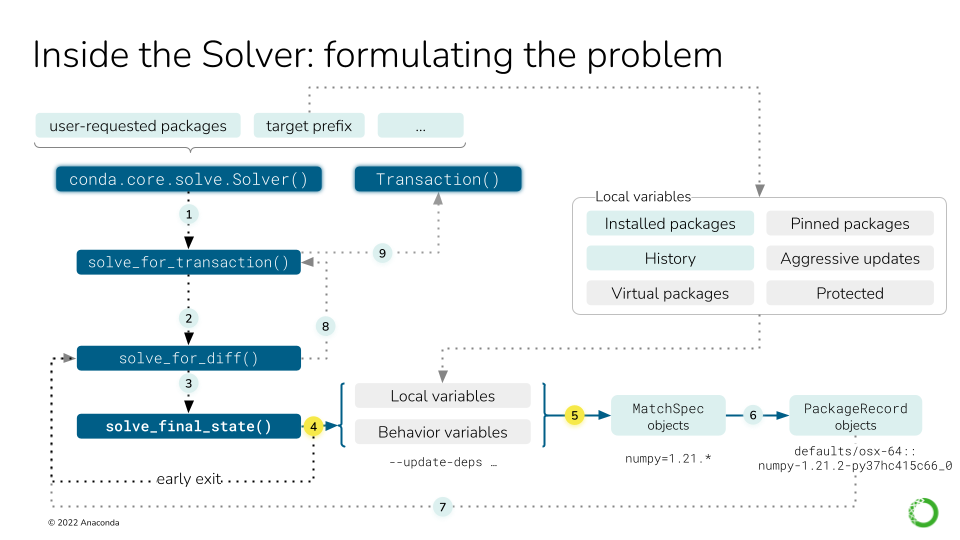
局部变量显式和隐式地影响求解过程。正如在 conda install 深入探讨 中看到的,主要参与者是 conda.core.solve.Solver 类。在调用 SAT 求解器之前,我们可以描述九个步骤:#
使用用户请求的软件包和活动环境 (目标前缀) 实例化
Solver类在实例上调用
solve_for_transaction()方法,该方法调用solve_for_diff()。调用
solve_final_state(),它从 CLI 获取更多参数。在某些情况下,我们可以提前返回 (例如,软件包已安装)。
如果我们没有提前返回,我们将所有局部变量收集到
MatchSpec对象列表中。
对于步骤 6 到 9,请参阅 此图。
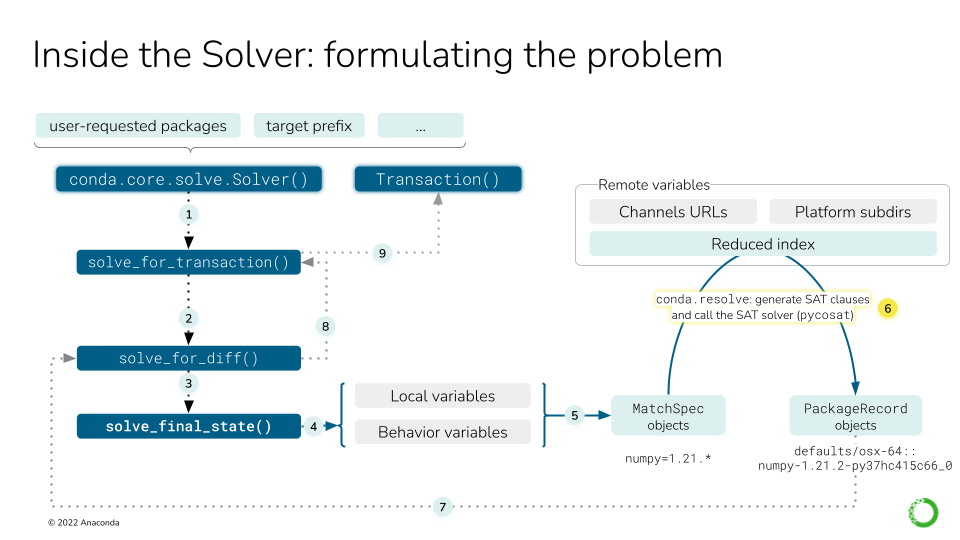
求解中的远程变量主要指软件包索引 (频道)。此图描述了九个步骤,重点是 6-9。对于步骤 1-5,请参阅 上图。#
现在需要获取所有频道,但必须聚合和缩减它们,以便求解器仅处理相关的部分。此步骤将“频道”转换为可用
PackageRecord对象列表。这是 SAT 求解器将要执行操作的地方。它将使用
MatchSpec对象列表从索引中选择一些PackageRecord条目,从而构建“已求解环境的最终状态”。如果您需要更多信息,将在本深入探讨指南的后面部分详细介绍。solve_for_diff获取最终状态,并将其与初始状态进行比较,生成它们之间的差异 (例如,软件包 A 已更新到版本 1.2,软件包 B 已删除)。solve_for_transaction获取差异和实例中的更多元数据,以生成Transaction对象。
conda.cli.install 中的高层级逻辑#
完整的求解器逻辑不是从 conda.core.solve.Solver API 开始的,而是在此之前,一直到 conda.cli.install 模块。在这里,已经做出了一些重要的决定:
是否根本不需要求解器,因为
操作是显式软件包安装
用户请求回滚到历史记录检查点
我们只是在创建现有环境的副本 (克隆)
使用哪个
repodata源 (参见 此处)。它不仅取决于当前配置 (通过.condarc或命令行标志),还取决于use_only_tar_bz2的值。求解器是否应首先冻结所有已安装的软件包 (现有环境中
conda install和conda remove的默认设置)。如果求解器找不到解决方案,我们是否需要再次重试,而不冻结当前
repodata变体的已安装软件包,或者我们是否应该尝试下一个变体。
因此,大致来说,那里的全局逻辑遵循以下伪代码:
if operation in (explicit, rollback, clone):
transaction = handle_without_solver()
else:
repodatas = from_config or ("current_repodata.json", "repodata.json")
freeze = (is_install or is_remove) and env_exists and update_modifier not in argv
for repodata in repodatas:
try:
transaction = solve_for_transaction(...)
except:
if repodata is last:
raise
elif freeze:
transaction = solve_for_transaction(freeze_installed=False)
else:
continue # try next repodata
handle_txn(transaction)
查看 此另一张图 以获得此伪代码的示意图。
然后,我们有两个理由重新运行完整的求解器逻辑:
冻结已安装的软件包不起作用,因此我们尝试不冻结再次尝试。
使用
current_repodata不起作用,因此我们尝试使用完整的repodata。
这两种策略是堆叠的,因此最终,在最终失败之前,我们将尝试四件事:
使用
current_repodata.json和freeze_installed=True求解使用
current_repodata.json和freeze_installed=False求解使用
repodata.json和freeze_installed=True求解使用
repodata.json和freeze_installed=False求解
有趣的是,这些策略旨在提高 conda 的平均性能,但它们应该被视为一种冒险的赌注。这些尝试可能会很昂贵!
如何请求更简单的方法
如果您想尝试完整的过程,而不检查优化的求解是否有效,您可以使用 conda install 命令中的这些标志覆盖默认行为:
--repodata-fn=repodata.json: 不使用current_repodata.json--update-specs: 不尝试冻结已安装的软件包
然后,Solver 类有其自己的内部逻辑,其中也包含一些重试循环。这将在稍后讨论和总结。
提前退出任务#
有些任务根本不涉及求解器。让我们枚举它们:
显式软件包安装:不需要索引或前缀状态。
克隆环境:如果缓存已清除,则可能需要索引。
历史记录回滚:目前已损坏。
强制删除:需要前缀状态。这发生在
Solver类中。如果已满足则跳过求解:需要前缀状态。这发生在
Solver类中。
显式软件包安装#
这些命令不需要求解器,因为请求的软件包使用直接 URL 或指向特定 tarball 的路径来表示。我们已经有了一个类似 PackageRecord 的实体,而不是 MatchSpec!为了使其工作,所有请求的软件包都需要是 URL 或路径。它们可以在命令行中键入,也可以在包含 @EXPLICIT 行的文本文件中键入。
由于求解器未参与,因此根本不处理显式软件包的依赖项。这可能会使环境处于不一致状态,可以通过运行 conda update --all 来修复,例如。
显式安装由 explicit 函数处理。
克隆环境#
conda create 有一个 --clone 标志,允许您创建现有环境的完整可工作副本。这是必需的,因为您不能使用 cp、mv 或您喜欢的文件管理器来重定位环境,否则会产生意想不到的后果。conda 环境中的某些文件可能包含指向原始位置中现有文件的硬编码路径,如果使用 cp 或 mv,这些引用将中断 (但是,conda 环境可以通过 conda rename 命令重命名;有关更多信息,请参见 以下章节)。
clone_env 函数实现了此功能。它本质上是获取源环境,为每个已安装的软件包生成 URL (过滤掉 conda、conda-env 及其依赖项),并将 URL 列表传递给 explicit()。如果源 tarball 不再在缓存中,它将查询索引以获得当前频道的最佳匹配。因此,副本并非完全是原始环境的克隆的可能性很小。
重命名环境#
当使用 conda rename 命令重命名已存在的环境时,请记住,求解器根本不会被调用,因为该命令本质上执行的是环境的 conda create --clone 和 conda remove --all。
历史记录回滚#
conda install 有一个 --revision 标志,允许您将环境状态恢复到以前的状态。这是通过 History 文件完成的,但其 当前实现 可以被认为是损坏的。一旦修复,我们将详细介绍它。
强制删除#
与显式安装类似,您可以删除软件包而无需执行完整的求解。如果使用 --force 调用 conda remove,则将直接删除指定的软件包,而无需分析其依赖树和修剪孤立项。这只能在查询活动前缀以获取已安装的软件包后发生,因此它在 Solver 类中处理。逻辑的这一部分返回 PackageRecord 对象列表,这些对象已在 PrefixData 列表中找到,并在过滤掉应删除的对象后返回。
如果已满足则跳过求解#
conda install 和 update 有一个相当晦涩的标志:-S, --satisfied-skip-solve
如果请求的规范已满足,则提前退出并且不运行求解器。还跳过由 'aggressive_update_packages' 配置的激进更新。类似于 'pip install' 的默认行为。
这也是在 Solver 级别实现 的,因为我们也需要 PrefixData 实例。它本质上是检查所有传递的 MatchSpec 对象是否可以匹配前缀中已有的 PackageRecord。如果是这种情况,我们将按原样返回已安装状态。否则,我们将继续进行完整的求解。
Solver.solve_final_state() 的详细信息#
注意
从此处开始,文档仅涵盖经典求解器逻辑 (它使用 pycosat)。libmamba 求解器有不同的方法,此处未记录。有关更多信息,请参阅 其文档。
这是定义 conda 逻辑的大部分复杂性的地方。在此步骤中,配置、命令行标志、用户请求的规范和前缀状态被聚合,以查询当前索引以获得最佳匹配。
所有这些状态位的聚合将产生 MatchSpec 对象列表。虽然很容易确定哪些软件包名称将进入列表,但决定规范携带的版本和构建字符串约束则稍微复杂一些。
这目前在 conda.core.solve.Solver 类中实现。其主要目标是填充 specs_map 字典,该字典将软件包名称 (str) 映射到 MatchSpec 对象。这发生在 .solve_final_state() 方法的开头。specs_map 填充的完整详细信息在 求解器状态技术规范 中介绍,但以下是涉及的子方法的小地图:
SolverStateContainer的初始化:通常缩写为ssc,它是一个辅助类,用于在尝试中存储一些状态 (请记住,有几个重试循环)。最重要的是,它存储两个关键属性 (以及其他属性):specs_map: 与上面相同。这是它在求解器尝试中存在的地方。solution_precs:PackageRecord对象列表。它存储 SAT 求解器返回的解决方案。它始终初始化为反映目标前缀中已安装的软件包。
Solver._collect_all_metadata(): 使用历史记录中找到的规范或与已安装记录对应的规范初始化specs_map。此方法委托给Solver._prepare()。这通过获取频道并缩减它来初始化索引。然后,使用该索引创建一个conda.resolve.Resolve实例。索引存储在Solver实例中,为._index,Resolve对象为._r。它们也保留在SolverStateContainer中,但作为公共属性:分别为.index和.r。Solver._remove_specs(): 如果调用了conda remove,它将从specs_map中删除相关的规范。Solver._add_specs():对于所有其他的conda命令(create、install、update),它将相关的 specs 添加(或修改)到specs_map中。 这是该类中最复杂的逻辑之一!
查看 Solver API 的其他部分
您可以在此处查看 Solver API 的其余部分。
此时,specs_map 已充分填充,我们可以调用由 conda.resolve.Resolve 类封装的 SAT 求解器。 这在 Solver._run_sat() 中完成,但此方法在实际解决 SAT 问题之前还会执行其他操作
在调用
._run_sat()之前,会通过Solver._find_inconsistent_packages执行不一致性分析。 如果Resolve.bad_installed()确定某些PackageRecord对象导致不一致,则会抢先从ssc.solution_precs中删除这些对象。 实际上,这会运行一系列小型求解来检查已安装的记录是否形成可满足的子句集。 那些阻止找到该解决方案的记录将被标记为如此,并在稍后的实际求解过程中被忽略。确保请求的软件包名称在索引中可用。
预测并最大限度地减少潜在的冲突 specs。 这在一个由
Resolve.get_conflicting_specs()驱动的while循环中发生。 如果发现某个 spec 冲突,则会中和它:创建一个新的MatchSpec对象,但没有版本和构建字符串约束(例如,numpy >=1.19变为仅numpy)。 然后,再次调用Resolve.get_conflicting_specs(),循环继续直到收敛:冲突列表无法进一步减少,要么是因为没有剩余冲突,要么是因为现有冲突无法通过约束放宽来解决。现在,调用 SAT 求解器。 这通过
Resolve.solve()完成。 更多内容见下文。如果求解器失败,则会引发
UnsatisfiableError。 根据我们所处的尝试阶段,conda将尝试使用非冻结的已安装软件包或不同的 repodata 再次尝试,或者它将放弃并分析冲突原因核心。 这将在稍后详细说明。如果求解器成功,则需要进行一些簿记工作
历史记录中碰巧存在的中和 specs 会被标记为如此。
不一致的软件包会重新添加到解决方案中,包括潜在的孤立软件包。
通过
Solver.get_constrained_packages()和Solver.determine_constricting_specs()运行约束分析,以帮助用户了解为什么某些软件包未更新。
不过,我们还没有完成。 在 Solver._run_sat() 之后,我们仍然需要运行后求解器逻辑! 求解后,如果设置了某些修饰符,则 PackageRecord 对象的最终列表可能仍会更改。 这在 Solver._post_sat_handling() 中处理
--no-deps(DepsModifier.NO_DEPS):从最终解决方案中删除显式请求的软件包的依赖项。--only-deps(DepsModifier.ONLY_DEPS):从最终解决方案中删除显式请求的软件包,但保留其依赖项。 这是通过PrefixGraph.remove_youngest_descendant_nodes_with_specs()完成的。--update-deps(UpdateModifier.UPDATE_DEPS):这是最有趣的一个。 它实际上运行第二次求解 (!),其中用户请求的 specs 是最初请求的 specs 加上它们的(现在已确定的)依赖项。--prune:从解决方案中删除孤立软件包。
Solver 还检查 Conda 更新
有趣的是,Solver API 还负责检查配置的通道中是否有新的 conda 版本可用。 此处执行此操作是为了利用索引已为该类的其余部分构建这一事实。
conda.resolve.Resolve 的详细信息#
这是实际封装 SAT 求解器的类。 conda.core.solve.Solver 是一个更高级别的 API,用于配置求解器请求并准备事务。 实际的解决方案是在我们现在讨论的另一个模块中计算的。
Resolve 对象主要接收两个参数
通过
conda.index.get_index()处理的已获取index。配置的
channels,以便可以理清通道优先级。
它还将保持某些状态
index将按名称分组在一个.groups字典 (str,[PackageRecord]) 下。 每个组稍后都会排序,以便较新的软件包首先列出,从而更好地减少索引。将创建另一个
PackageRecord组字典,按其track_features条目键入,位于.trackers属性下。一些其他字典被初始化为缓存。
此类中的主要方法是
bad_installed():此方法使用一系列小型求解来检查已安装的软件包是否处于一致状态。 换句话说,如果所有PackageRecord条目都表示为MatchSpec对象,则环境是否可解?get_reduced_index():此方法采用完整索引并修剪掉当前请求不需要的部分,从而缩小解决方案空间并加快求解器的速度。gen_clauses():此方法实例化并配置Clauses对象,它是真正的 SAT 求解器包装器。 更多内容稍后介绍。solve():Resolve类中的主要方法。 将在下一节中讨论。find_conflicts():如果求解器未成功,则此方法执行冲突分析,以找到当前冲突的最合理的解释。 它主要依赖于build_conflict_map()来“查找可能是冲突原因的公共依赖项”。conda可能会在此方法中花费大量时间。
禁用冲突分析
可以通过 context.unsatisfiable_hints 选项禁用冲突分析,但不幸的是,这会妨碍 conda 的迭代逻辑。 它会在尝试链中尽早快捷,并阻止求解器尝试约束较少的 specs。 这是应该改进的逻辑的一部分。
Resolve.solve()#
如上所述,这是 Resolve 类中的主要方法。 它将执行以下操作
通过
get_reduced_index减少索引。 如果不成功,请尝试检测是否缺少软件包或请求了错误的版本。 我们可以尽早引发异常以触发conda.cli.install中的新尝试(记住,非冻结或下一个 repodata),或者,如果是最后一次尝试,我们将直接转到find_conflicts()以了解哪里出了问题。使用缩减的索引实例化一个新的
Resolve对象,以通过gen_clauses()生成Clauses对象。 此方法依赖于push_MatchSpec()将MatchSpec对象转换为Clauses对象(称为C)内的 SAT 子句。运行
Clauses.sat()以解决 SAT 问题。 如果找不到解决方案,请以通常的方式处理错误:尽早引发异常以触发另一次尝试或调用find_conflicts()以尝试解释原因。如果未找到错误,则我们有一个或多个可用的解决方案,我们需要对它们进行后处理以找到最佳解决方案。 这是分几个步骤完成的
最大限度地减少删除的软件包数量。 SAT 子句通过
Resolve.generate_removal_count()生成,然后Clauses.minimize()将使用它来优化当前解决方案。最大限度地提高解决方案中每个记录与 spec 的匹配程度。 SAT 子句现在在
Resolve.generate_version_metrics()中生成。 这会返回五组子句:通道、版本、构建、arch 或 noarch 以及时间戳。 此时,仅优化通道和版本。最大限度地减少具有
track_feature条目的记录数。 SAT 子句来自Resolve.generate_feature_count()。最大限度地减少具有
features条目的记录数。 SAT 子句来自Resolve.generate_feature_metric()。现在,我们继续在 (2) 中开始的工作。 我们将最大限度地提高构建号,并选择特定于 arch 的软件包而不是 noarch 变体。
我们还希望在解决方案中包含尽可能多的可选 specs。 感谢
Resolve.generate_install_count()生成的子句,对此进行优化。同时,如果保留已安装的版本也满足请求,我们将最大限度地减少必要的更新次数。 使用
Resolve.generate_update_count()生成的子句。步骤 (2) 和 (5) 也适用于间接依赖项。
最大限度地减少解决方案中的软件包数量。 这是通过删除不必要的软件包来完成的。
最后,最大限度地提高时间戳直到收敛,以便首选最新的软件包。
此时,SAT 解决方案索引可以转换回SAT 名称。 这是在您可以在
Resolve.sat()中找到的clean()局部函数中完成的。我们有可能找到问题的备用解决方案,现在正在探索这一点,但最终只会返回第一个解决方案,同时将SAT 名称转换为
PackageRecord对象。
Clauses 对象使用多个层封装 SAT 求解器#
Resolve 类公开了求解逻辑,但当涉及到与 SAT 求解器引擎交互时,这是通过 Clauses 对象树完成的。 我们说“树”是因为实际的引擎封装在多个层中
Resolve根据需要生成conda.common.logic.Clauses对象。Clauses是对其私有conda.common._logic.Clauses对等物的紧密包装器。 让我们将前者称为_Clauses。 它只是使用._eval()调用和其他便捷快捷方式包装_ClausesAPI。_Clauses提供了一个 API 来处理原始 SAT 公式或子句。 它将包装conda.common._logic._SatSolver子类之一。 这些是封装 SAT 求解器引擎的子类! 到目前为止,有三个子类,可以通过context.sat_solver设置选择_PycoSatSolver,键为pycosat。 这是默认的,是 Python 包装器,围绕picosat项目。_PySatSolver,键为pysat。 使用在pysat项目中找到的Glucose4求解器。_PyCryptoSatSolver,键为pycryptosat。 使用 CryptoMiniSat 项目的 Python 绑定。
原则上,如果使用订阅 _SatSolver API 的包装器,则可以将更多 SAT 求解器添加到 conda 中。 但是,如果原因是选择性能更好的引擎,请考虑以下几点
封装的 SAT 求解器已在使用编译语言。
生成子句确实是用纯 Python 编写的,并且具有不可忽略的开销。
如果“赌注”不成功,则像减少索引和约束解决方案空间这样的优化技巧会产生成本。
有关 SAT 求解器的更多信息(一般)
本指南未涵盖 SAT 求解器是什么或做什么的详细信息。 如果您想阅读有关它们的信息,请考虑查看以下资源
Aaron Meurer 关于 Conda 内部原理的幻灯片。 这些幻灯片揭示了 2015 年
conda的许多细节。 有些事情发生了变化,但核心 SAT 求解器行为仍然在那里得到了很好的解释。Packaging-Con 2021 中所有关于求解器的演讲。 查看哪些演讲属于求解器轨道并享受!
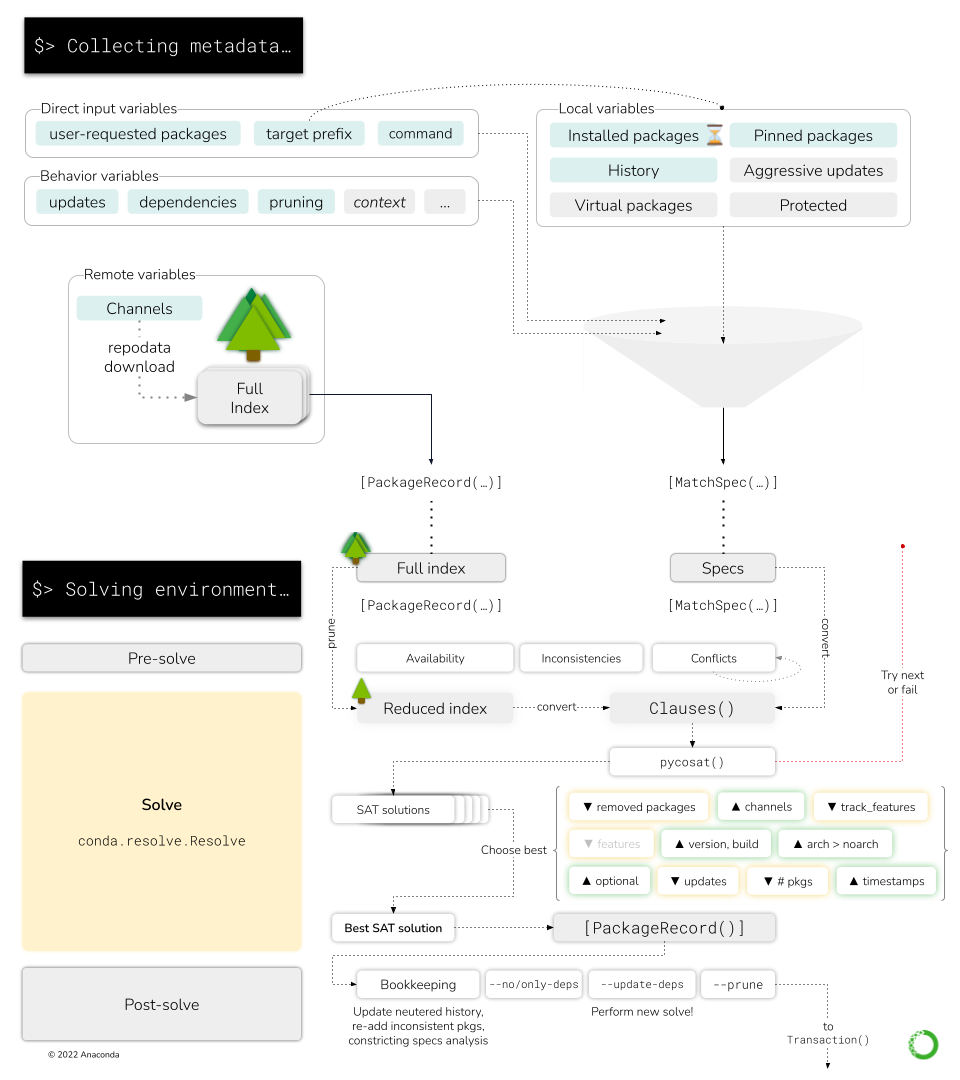
在此处,您可以看到高级 Solver API 如何与低级 Resolve 和 Clauses 对象交互。#
CLI 报告中的收集元数据步骤仅编译来自 CLI 参数、前缀状态和所选通道的必要信息,为 SAT 求解器适配器提供两条关键信息
MatchSpec对象列表(“用户在此环境中想要的内容”)PackageRecord对象列表(“通道中可用的软件包”)
因此,本质上,SAT 求解器采用 MatchSpec 对象来选择哪些 PackageRecord 对象以最佳方式满足用户请求。 必要的计算是 CLI 报告中“解决环境…”步骤的一部分。