conda install#
在本文档中,我们将探讨从用户输入安装命令到过程成功完成,Conda 中会发生什么。为了完整起见,我们将考虑以下情况
用户正在 Linux x64 机器上运行命令,该机器上已安装可用的 Miniconda。
这意味着我们有一个
base环境,其中包含conda、python及其依赖项。base环境已为 Bash 预激活。有关激活的更多详细信息,请查看 conda init 和 conda activate。
好的,那么... 当您运行 conda install numpy 时会发生什么?大致来说,这些步骤
命令行界面
argparse解析器环境变量
配置文件
上下文初始化
任务委派
获取索引
检索所有通道和平台
关于通道优先级的说明
解决安装请求
请求的包 + 前缀状态 = 规范列表
索引缩减(有时)
运行求解器
后处理包列表
生成事务和相应的操作
下载和提取
完整性验证
链接和取消链接文件
后链接和后激活任务
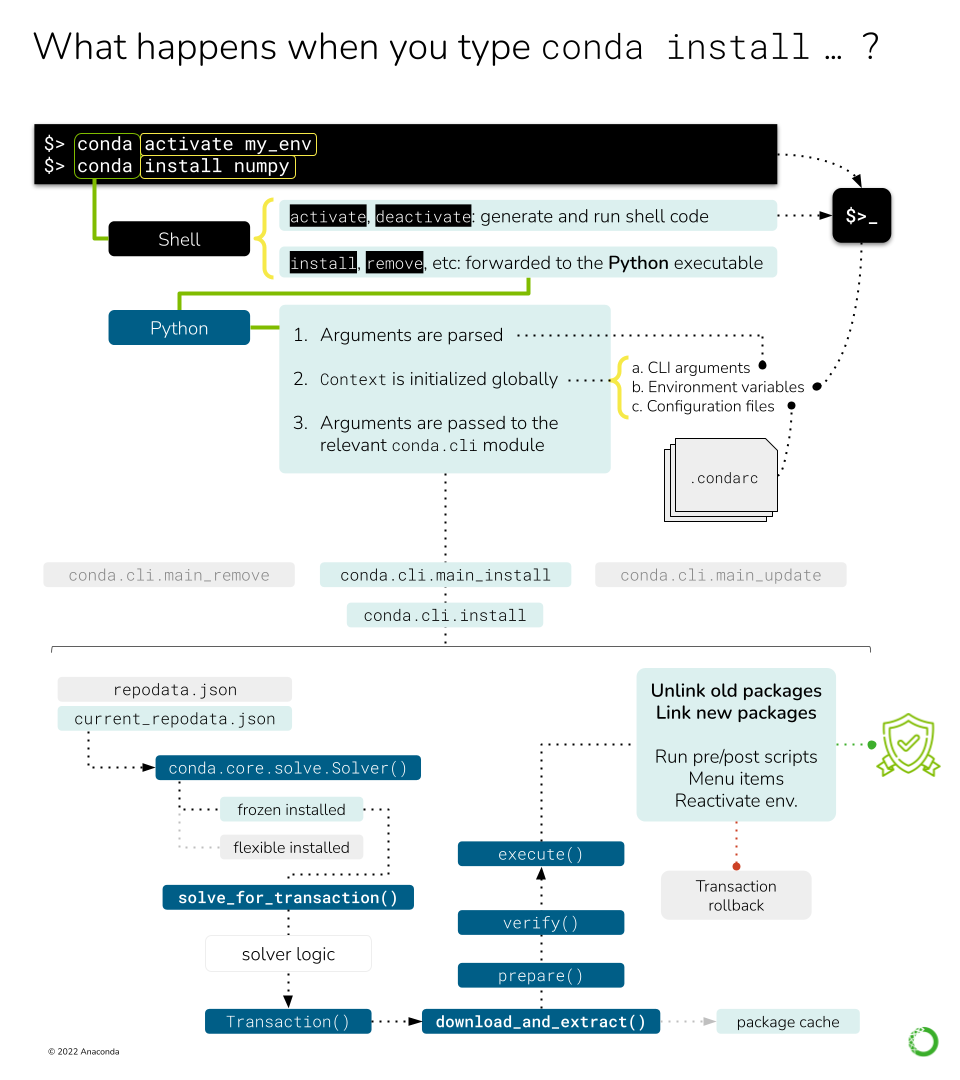
此图显示了处理简单 conda install 命令所涉及的不同过程和对象。#
命令行界面#
首先,关于一个可能不明显的实现细节的快速说明。
当您在终端中键入 conda install numpy 时,Bash 会获取这三个词,并查找 conda 命令以传递参数列表 ['conda', 'install', 'numpy']。在找到位于 CONDA_HOME/condabin 的 conda 可执行文件之前,它可能会找到 此处定义的 shell 函数。如果请求,此 shell 函数会在 shell 上运行激活/停用逻辑,否则会委派给实际的 Python 入口点。可以在 conda.shell 中找到此逻辑部分。
一旦我们运行 Python 入口点,我们就进入了 conda.cli 领域。入口点调用的函数是 conda.cli.main:main()。在这里,再次检查 shell.* 子命令,这些子命令生成您在 ~/.bashrc 和其他文件中看到的 shell 初始化程序。如果您好奇这种情况发生在何处,请查看 conda.activate。
由于我们的命令是 conda install ...,我们仍然需要到达其他地方。您会注意到,其余逻辑委托给 conda.cli.main:_main(),它将调用解析器生成器,初始化上下文和记录器,并最终将参数列表传递给相应的命令函数。这四个步骤在四个函数/类中实现
conda.cli.conda_argparse:generate_parser():这使用argparse生成 CLI。每个子命令都在单独的函数中初始化。请注意,命令行选项不是从Context对象动态生成的,而是手动注释的。如果需要这样做(例如,--repodata-fn在Context.repodata_fn中公开),则每个 CLI 选项的dest变量应 匹配上下文对象中的目标属性。conda.base.context.Context:此对象存储conda中的配置选项,并将被初始化,其中除其他外,还要考虑在上述步骤中解析的参数。这在单独的深入探讨中进行了更详细的介绍:conda config 和上下文。conda.gateways.logging:initialize_logging():不太令人兴奋且易于理解。代码库的这一部分或多或少是不言自明的。conda.cli.conda_argparse:do_call():参数解析将填充一个func值,其中包含负责该子命令的函数的导入路径。例如,conda install由 处理,由conda.cli.main_install处理。按照设计,func报告的所有模块都必须包含一个实现命令逻辑的execute()函数。execute()接受解析后的参数和解析器本身作为参数。例如,在conda install的情况下,execute()仅 重定向 到conda.cli.install:install()中的某种模式。
现在让我们看一下该模块。conda.cli.install:install() 实现了 conda create、conda install、conda update 和 conda remove 背后的逻辑。本质上,它们都处理相同的任务:更改环境中存在的包。如果您去阅读该函数,您将看到有几行代码处理各种情况(新环境、克隆等),然后我们到达下一节。我们不会在此处讨论它们,但请随意探索 该部分。它主要确保目标前缀存在,我们是否正在创建新环境以及按摩某些命令行标志,这些标志将允许我们跳过求解器(例如 --clone)。
有关环境的更多信息
查看 环境 的概念。
获取索引#
在此时,我们准备好开始做一些工作了!之前所有的代码都在告诉我们要做什么,而现在我们知道了。我们希望 conda 在我们的 base 环境中安装 numpy。我们首先需要知道的是在哪里可以找到名为 numpy 的软件包。答案是……通道!
用户从 conda 通道下载软件包。这些通道通常托管在 anaconda.org 上。一个通道本质上是一个包含以下元素的目录结构
<channel>
├── channeldata.json
├── index.html
├── <platform> (e.g. linux-64)
│ ├── current_repodata.json
│ ├── current_repodata.json.bz2
│ ├── index.html
│ ├── repodata.json
│ ├── repodata.json.bz2
│ ├── repodata_from_packages.json
│ └── repodata_from_packages.json.bz2
└── noarch
├── current_repodata.json
├── current_repodata.json.bz2
├── index.html
├── repodata.json
├── repodata.json.bz2
├── repodata_from_packages.json
└── repodata_from_packages.json.bz2
更多关于通道的信息
您可以在 “通道”是什么? 和 仓库结构和索引 中找到更多面向用户的关于通道的说明。如果您对更多技术细节感兴趣,请查看 conda-build 的文档页面。
重要的部分是
一个通道包含一个或多个平台特定的目录(
linux-64、osx-64等),以及一个名为noarch的平台无关目录。在conda术语中,这些也被称为通道子目录。官方来说,noarch子目录足以使其成为一个conda通道;例如,不需要平台子目录。每个子目录至少包含一个
repodata.json文件:这是一个巨大的字典,其中包含该平台上每个可用软件包的所有元数据。在大多数情况下,相同的子目录也包含每个已发布软件包的
*.tar.bz2文件。这是conda在完成求解后下载和解压的内容。这些文件的结构在内容和命名结构上都有明确的定义。有关更多详细信息,请参阅 什么是软件包?、软件包元数据 和/或 软件包命名约定。
此外,通道的主目录可能包含一个 channeldata.json 文件,其中包含通道范围的元数据(这不是特定于平台的)。并非所有通道都包含此文件,并且通常它目前不是常用的内容。
由于 conda 的理念是保留所有已发布的软件包以实现可重现性,因此 repodata.json 始终在增长,这给下载本身和求解器引擎都带来了问题。为了减少下载时间和带宽使用,repodata.json 也以 BZIP2 压缩文件 repodata.json.bz2 的形式提供。这是大多数 conda 客户端最终下载的内容。
关于 ‘current_repodata.json’ 的说明
在某些通道中可以找到更多 repodatas 变体,但为了性能,它们始终是主版本的简化版本。例如,current_repodata.json 仅包含每个软件包的最新版本及其依赖项。关于此优化技巧的基本原理可以在这里找到。
因此,本质上,获取通道信息意味着可以用如下伪代码表示
platform = {}
noarch = {}
for channel in reversed(context.channels):
platform_repodata = fetch_extract_and_read(
channel.full_url / context.subdir / "repodata.json.bz2"
)
platform.update(platform_repodata)
noarch_repodata = fetch_extract_and_read(
channel.full_url / "noarch" / "repodata.json.bz2"
)
noarch.update(noarch_repodata)
请注意,这些字典以文件名为键,因此优先级较高的通道将覆盖具有完全相同文件名的条目(例如,numpy-1.19-py36h87ha43_0.tar.bz2)。如果它们没有相同的文件名(例如,相同的版本和构建号但哈希值不同),则此歧义将在稍后的求解器中解决,并考虑通道优先级模式。
在此示例中,context.channels 已通过不同的级联机制填充
在
~/.condarc或等效文件中找到的默认设置。CONDA_CHANNELS环境变量(很少使用)。命令行标志,例如
-c <channel>、--use-local或--override-channels。命令行 spec 中存在的通道。请记住,用户可以说
channel::numpy而不是简单地numpy来要求 numpy 来自该特定通道。这意味着也需要获取该通道的 repodata!
context.channels 中的项应该是 conda.models.channels.Channel 对象,但 Solver API 也允许引用其名称、别名或完整 URL 的字符串。在这种情况下,您可以使用 Channel 对象来解析和检索每个子目录的完整 URL,方法是使用 Channel.urls() 方法。如果需要,可以在 conda.core.index 中找到几个辅助函数。
遗憾的是,fetch_extract_and_read() 并不以这种形式存在,而是以对象的组合形式存在。主要的驱动函数实际上是 get_index(),它将通道 URL 传递给 fetch_index,后者是一个直接委托给 conda.core.subdir_data.SubdirData 对象的包装器。此对象实现了缓存、身份验证、代理以及其他使 “只需下载文件,拜托” 这种简单想法变得复杂的事情。大部分逻辑都在 SubdirData._load() 中,它最终调用 conda.core.subdir_data.fetch_repodata_remote_request() 来处理请求。最后,SubdirData._process_raw_repodata_str() 执行解析和加载。
在内部,SubdirData 将所有软件包元数据存储为 PackageRecord 对象列表。它的主要用法是通过 .query() (一次一个结果)或 .query_all() (所有可能的匹配项)。这些 .query* 方法接受 spec 字符串(例如 numpy =1.14)、MatchSpec 和 PackageRecord 实例。或者,如果您想要所有记录而无需查询,请使用 SubdirData.iter_records()。
减小索引大小的技巧
conda 支持尝试使用不同版本的索引,以努力最小化解决方案空间的概念。毕竟,较小的索引意味着更快的搜索!默认逻辑从通道中的 current_repodata.json 文件开始,这些文件仅包含每个软件包的最新版本及其依赖项。如果失败,则使用完整的 repodata.json。这发生在甚至在 Solver 被调用之前。
第二个技巧是在经典求解器逻辑 (pycosat) 中完成的:知情的索引缩减。本质上,索引(无论是 current_repodata.json 还是完整的 repodata.json)由求解器修剪,尝试仅保留它预计需要的部件。更多详细信息可以在 get_reduced_index 函数中找到。有趣的是,这种优化步骤也需要更长的时间,索引越大。
通道优先级#
context.channels 返回 Channel 对象的 IndexedSet;本质上是一个唯一项列表。此列表中的不同通道对于相同的软件包名称可能具有重叠甚至冲突的信息。例如,defaults 和 conda-forge 肯定会包含满足 conda install numpy 请求的软件包。在这种情况下,conda 选择哪一个?这取决于 context.channel_priority 设置:来自帮助消息
接受 ‘strict’、‘flexible’ 和 ‘disabled’ 值。默认值为 ‘flexible’。使用严格的通道优先级,如果优先级较高的通道中出现同名软件包,则不考虑优先级较低的通道中的软件包。使用灵活的通道优先级,求解器可能会访问优先级较低的通道以满足依赖关系,而不是引发无法满足的错误。禁用通道优先级后,软件包版本优先,通道的配置优先级仅用于打破僵局。
在实践中,对于大多数用户来说,channel_priority=strict 通常是推荐的设置。它求解速度更快,并且在后续过程中产生的问题更少。在此处查看更多详细信息 here。
解决安装请求#
此时,我们可以开始向求解器询问事情了。毕竟,我们已将通道加载到索引中,构建了我们可以安装的可用软件包和版本的目录。我们还具有自定义求解器请求所需的命令行指令和配置。因此,让我们开始做吧:“求解器,请使用这些通道作为软件包来源,在此前缀上安装 numpy。”
细节很复杂,但本质上,Solver 将会
将请求的软件包、命令行选项和前缀状态表示为
MatchSpec对象查询索引以获得满足这些约束的最佳可能匹配项
返回
PackageRecord对象列表
如果您有兴趣,完整的详细信息将在 求解器 中介绍。请记住,第 (1) 点是 conda 特有的,而原则上,(2) 可以由任何 SAT 求解器解决。
生成事务和相应的操作#
Solver API 定义了三个公共方法
.solve_final_state():这是核心函数,如上节所述。给定一些输入状态,它返回一个PackageRecord对象的IndexedSet,反映环境的最终状态应为何样。这是最大的方法,其详细信息在 此处 完整介绍。.solve_for_diff():此方法获取最终状态,并将其与环境的当前状态进行比较,从而发现哪些旧记录需要删除,以及哪些新记录需要添加。.solve_for_transaction():此方法获取差异,并为此操作创建一个Transaction对象。这是主 CLI 逻辑期望从求解器返回的内容。
那么什么是 Transaction 对象,为什么需要它?事务性操作 在 conda 4.3 中引入。它们似乎是一组旨在检查 conda 是否能够下载和链接所需软件包的更改的最后一次迭代(例如,检查磁盘上是否有足够的空间,用户是否对目标路径具有足够的权限等)。有关更多信息,请参阅 PR #3571、#3301 和 #3034。
事务本质上是一组 action 对象。每个 action 都可以运行一些检查,以确定它是否可以成功执行。如果情况并非如此,失败的检查将向父事务发出信号,表明整个操作需要中止并回滚,以使事物恢复到运行 conda 命令之前的状态。它还负责你在 CLI 输出中看到的一些消息,例如将要安装、更新或删除的报告。
事务和并行性
由于事务对象知道所有需要发生的 action,因此它还支持并行地进行验证、下载和(取消)链接任务。并行级别可以通过以下 context 设置进行更改
default_threadsverify_threadsexecute_threadsrepodata_threadsfetch_threads
conda 中只有一种事务类:LinkUnlinkTransaction。它只接受一个输入参数:PrefixSetup 对象列表,这些对象只是具有以下字段的 namedtuple 对象。这些字段由 Solver.solve_for_transaction 在运行 Solver.solve_for_diff 后填充。
target_prefix:命令正在运行的环境路径。unlink_precs:需要取消链接(删除)的PackageRecord对象。link_precs:需要链接(添加)的PackageRecord对象。remove_specs:需要在历史记录中标记为已删除的MatchSpec对象(用户要求卸载这些软件包)。update_specs:需要在历史记录中标记为已添加的MatchSpec对象(用户要求安装或更新这些软件包)。neutered_specs:已经在历史记录中但为了避免解决冲突而不得不放宽限制的MatchSpec对象。
实例化之后会发生什么取决于这些 PrefixSetup 对象的内容。有时,事务不会导致任何 action(请参阅 nothing_to_do 属性),因为用户请求的内容已通过环境的当前状态满足。
但是,大多数时候,事务将涉及许多 action。这通过两个公共方法完成
download_and_extract():本质上是实例化和调用ProgressiveFetchExtract的转发器,负责决定哪些PackageRecords需要下载并提取到软件包缓存。execute():核心逻辑在这里布局。它涉及准备、验证和执行其余的 action。其中包括取消链接软件包(从环境中删除软件包)
链接(向环境中添加软件包)
编译字节码(为每个
py模块生成pyc副本)添加入口点(为配置的函数生成命令行可执行文件)
添加 JSON 记录(对于每个软件包,都会向
conda-meta/添加一个 JSON 文件)创建菜单项(为
Menu/下具有 JSON 文件的软件包创建快捷方式)删除菜单项(删除该软件包创建的快捷方式)
重要的是要注意,下载和提取与所有其他 action 分开进行。这种分离非常重要,并且是 conda 环境概念的核心。本质上,当你创建一个新的 conda 环境时,你不一定是在将文件复制到目标前缀位置。相反,conda 维护一个磁盘上每个已下载软件包的缓存(包括 tarball 和提取的内容)。为了节省空间并加快环境创建和删除速度,文件不会被复制,而是被链接(通常通过硬链接)。这就是为什么这两个任务在事务逻辑中是分开的:你不需要下载和提取缓存中已有的软件包;你只需要链接它们!
事务还驱动报告
action 的类型和数量也可以通过 _make_legacy_action_groups() 计算,它返回一个action 组列表(每个 PrefixSetup 一个)。每个 action 组只是一个遵循此规范的字典
{
"FETCH": Iterable[PackageRecord], # estimated by `ProgressiveFetchExtract`
"PREFIX": str,
"UNLINK": Iterable[PackageRecord],
"LINK: Iterable[PackageRecord],
}
这些更简单的 action 组仅用于报告,可以通过处理后的文本报告(通过 print_transaction_summary)或原始 JSON(通过 stdout_json_success)。正如你所看到的,它们不了解任何其他类型的任务。
下载和提取#
conda 维护已下载 tarball 及其提取内容的缓存,以节省磁盘空间并提高环境修改的性能。这需要一些代码来检查给定的 PackageRecord 是否已存在于缓存中,如果不存在,则需要代码以高性能的方式下载 tarball 并提取其内容。这一切都由 ProgressiveFetchExtract 类处理,该类可以为每个传递的 PackageRecord 实例化最多两个 Action 对象
CacheUrlAction:将 tarball 下载(如果远程)或复制(如果本地)到缓存位置。ExtractPackageAction:提取 tarball 的内容。
这两个 action 仅在软件包尚未在缓存中且尚未提取时才发生。如果事务中止(由于错误或用户按下 Ctrl+C),它们也可以还原更改。
填充前缀#
当所有必需的软件包都已下载并提取到缓存后,就该开始使用所需的文件填充前缀了。这意味着我们需要
对于每个需要取消链接的软件包,运行预取消链接逻辑(
deactivate和pre-unlink脚本,以及快捷方式删除,如果需要),然后取消链接软件包文件。对于每个需要链接的软件包,创建链接并运行后链接逻辑(
post-link和activate脚本,以及创建快捷方式,如果需要)。
请注意,当你更新软件包版本时,实际上是完全删除已安装的版本,然后添加新版本。换句话说,更新只是取消链接+链接。
这是如何实现的?对于传递给 UnlinkLinkTransaction 的每个 PrefixSetup 对象,将实例化许多 ActionGroup 命名元组(每个任务类别一个),并将它们分组到 PrefixActionGroup 命名元组中。然后将这些传递给 .verify()。此方法将获取每个 action,运行其检查,如果所有检查都通过,则允许我们在 .execute() 中执行实际执行。如果其中一个失败,则可以中止事务并回滚。
为了使所有这些工作正常进行,每个 action 对象都遵循 PathAction API 约定
class PathAction:
_verified = False
def verify(self):
"Run checks to assess if the action can proceed"
def execute(self):
"Perform the action"
def reverse(self):
"Undo execute"
def cleanup(self):
"Remove artifacts from verification, execution or reversal"
@property
def verified(self):
"True if verification was run and successful"
额外的 PathAction 子类将添加更多方法和属性,但这就是事务执行逻辑所期望的。为了支持填充前缀中涉及的所有不同 action,PathAction 类树包含相当多的图形
PathAction
PrefixPathAction
CreateInPrefixPathAction
LinkPathAction
PrefixReplaceLinkAction
MakeMenuAction
CreatePythonEntryPointAction
CreatePrefixRecordAction
UpdateHistoryAction
RemoveFromPrefixPathAction
UnlinkPathAction
RemoveLinkedPackageRecordAction
RemoveMenuAction
RegisterEnvironmentLocationAction
UnregisterEnvironmentLocationAction
CacheUrlAction
ExtractPackageAction
MultiPathAction
CompileMultiPycAction
AggregateCompileMultiPycAction
欢迎你阅读每个类的文档字符串,以了解每个类正在做什么;所有这些类都列在 conda.core.path_actions 下。在以下各节中,我们将仅评论最重要的类。
链接环境中的文件#
当 conda 将文件从缓存位置链接到前缀位置时,它实际上可能意味着三个不同的 action
创建软链接
创建硬链接
复制文件
软链接和硬链接之间的区别是微妙但重要的。你可以在其他地方找到有关差异的更多信息(例如,这里),但对于我们的目的而言,这意味着
硬链接解析成本较低,行为类似于真实文件,但只能链接同一挂载点中的文件。
软链接可以跨挂载点链接文件,但它们的行为并不完全像文件(更像是转发器),因此它们可能会破坏某些代码中做出的假设。
大多数时候,conda 会尝试硬链接文件,如果失败,则会复制它们。复制文件是一项昂贵的磁盘操作,无论是在时间和空间方面,因此它应该是最后的选择。但是,有时这是唯一的方法。特别是,当文件需要修改才能在目标前缀中使用时。
嗯……什么?为什么 conda 会修改文件来安装它?这与可重定位性有关。当创建 conda 软件包时,conda-build 最多创建三个临时环境
构建环境:安装编译器和其他构建工具的位置,与主机环境分开,以支持交叉编译。
主机环境:安装构建时依赖项的位置,以及你正在构建的软件包。
测试环境:安装运行时依赖项的位置,以及你刚刚构建的软件包。它模拟用户安装软件包时会发生的情况,因此你可以对软件包运行任意检查。
当你构建软件包时,对构建时路径的引用可能会泄漏到某些文件(包括文本和二进制文件)的内容中。对于从源代码构建自己的软件包的用户来说,这不是问题,因为他们可以选择此路径并将文件留在那里。但是,对于 conda 软件包来说,几乎永远不是这样。它们在一台机器上创建,然后在另一台机器上安装。为了避免“找不到路径”问题和其他问题,conda-build 通过将对构建时路径的引用替换为占位符来标记那些包含引用的软件包。在安装时,conda 会将这些占位符替换为目标前缀,一切正常!
但有一个问题:我们无法修改缓存位置上的文件,因为它们可能在不同环境(显然具有不同的路径)之间使用。在这些情况下,文件不会被链接,而是被复制;路径替换当然只发生在目标副本上!
conda 如何知道如何链接给定的软件包,或者更准确地说,如何链接其提取的文件?所有这些都在 UnlinkLinkTransaction._prepare() 中的准备例程(更具体地说,通过 determine_link_type())以及 LinkPathAction.create_file_link_actions() 中确定。
请注意,(取消)链接 action 还包括预(取消)链接和后(取消)链接脚本的执行(如果已列出)。
action 组和 action,详细信息#
一旦旧软件包被删除,新软件包通过适当的方式链接,我们就完成了,对吗?还没!还剩一个步骤:后链接逻辑。
事实证明,为了使 conda 如此方便易用,需要完成许多较小的任务。您可以在上面几个段落中找到所有这些任务的列表,但我们也会在这里介绍它们。执行顺序在 UnlinLinkTransaction._execute 中确定。所有可能的组都列在 PrefixActionGroup 下。它们的顺序大致是它们在实践中发生的顺序
remove_menu_action_groups,由RemoveMenuAction动作组成。unlink_action_groups,包括UnlinkPathAction、RemoveLinkedPackageRecordAction,以及运行 pre- 和 post-unlink 脚本的逻辑。unregister_action_groups,基本上是一个UnregisterEnvironmentLocationAction动作。link_action_groups,包括LinkPathAction、PrefixReplaceLinkAction,以及运行 pre- 和 post-link 脚本的逻辑。entry_point_action_groups,CreatePythonEntryPointAction动作的集合。register_action_groups,一个RegisterEnvironmentLocationAction动作。compile_action_groups,几个CompileMultiPycAction最终聚合为一个AggregateCompileMultiPycAction以提高性能。make_menu_action_groups,由MakeMenuAction动作组成。prefix_record_groups,通过CreatePrefixRecordAction动作记录环境中已安装的软件包。
让我们讨论一下本指南中描述的命令的这些动作组:conda install numpy。求解器给出的解决方案表明我们需要
取消链接 Python 3.9.6
链接 Python 3.9.9
链接 numpy 1.19
这就是将会发生的事情
没有菜单项被移除,因为 Python 3.9.6 没有创建任何菜单项。
Python 3.9.6 的 pre-unlink 脚本会运行,但在此例中没有脚本。
Python 3.9.6 文件将从环境中移除。这可以并行处理。
Post-unlink 脚本会运行(如果有)。
Python 3.9.9 和 numpy 1.19 的 pre-link 脚本会运行(如果有)。
Python 3.9.9 和 numpy 1.19 软件包中的文件将被链接和/或复制到 prefix。这可以并行处理。
将为新软件包创建入口点(如果有)。
Post-link 脚本会运行。
将为新软件包生成
pyc文件。新软件包将在
conda-meta/下注册。将为新软件包创建菜单快捷方式(如果有)。
任何这些步骤都可能因给定的异常而失败。如果是这种情况,则第一个异常将打印到 STDOUT。此外,如果 rollback_enabled 在 context 中配置正确,则事务将通过从最后一个到第一个调用每个动作中的 .reverse() 方法来回滚。
如果没有报告异常,则动作可以运行其清理程序。
就是这样!如果此命令导致创建新环境,您将收到一条消息,告诉您如何激活新创建的环境。
结论#
这就是您键入 conda install 时发生的事情。它可能比您最初想象的要复杂一些,但一切都归结为以下几个步骤。简而言之:
解析参数并初始化上下文
下载并构建索引
告诉求解器我们想要什么
将解决方案转换为事务
验证并运行事务中包含的每个动作